Introduction
GEMM, General Matrix Multiplication.
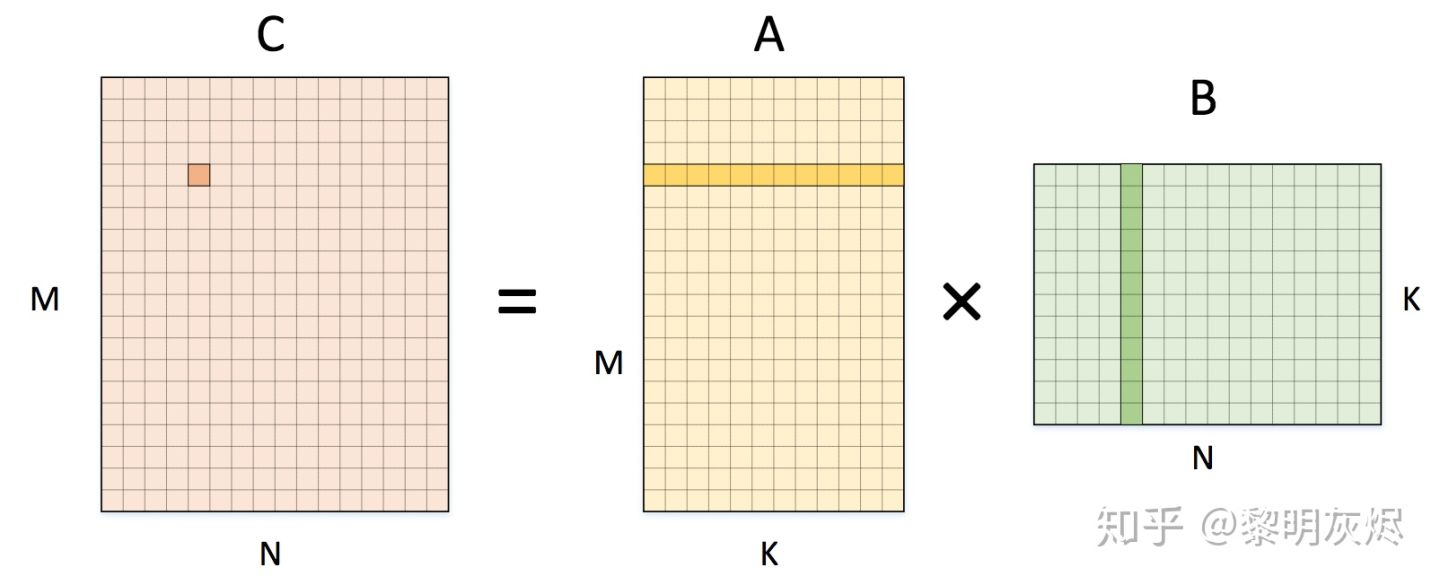 伪代码 :
伪代码 :
for (int m = 0; m < M; m++) { // spatial axis
for (int n = 0; n < N; n++) { // spatial axis
C[m][n] = 0;
for (int k = 0; k < K; k++) { // reduction axis
C[m][n] += A[m][k] * B[k][n];
}
}
}
优化思路:
- 基于算法分析的方法:根据矩阵乘计算特性,从数学角度出发,典型算法包括 Strassen 算法和 Coppersmith-Winograd 算法
- 基于软件优化的方法:根据计算机存储系统的层次结构特性,选择性的调整计算顺序,主要有循环拆分、向量化、内存重排等
基于算法分析的方法
Strassen 算法
- 分治:
- 辅助矩阵:
- 结合:
Coppersmith-Winograd 算法
基于软件优化的方法
矩阵乘的计算操作总数为 ,内存访问总数为 ,对于矩阵 C 必须要先读取内存,累加完毕后再存储(忽略了对 C 初始化的操作)。
计算拆分
拆分为 1✖️4的小块:
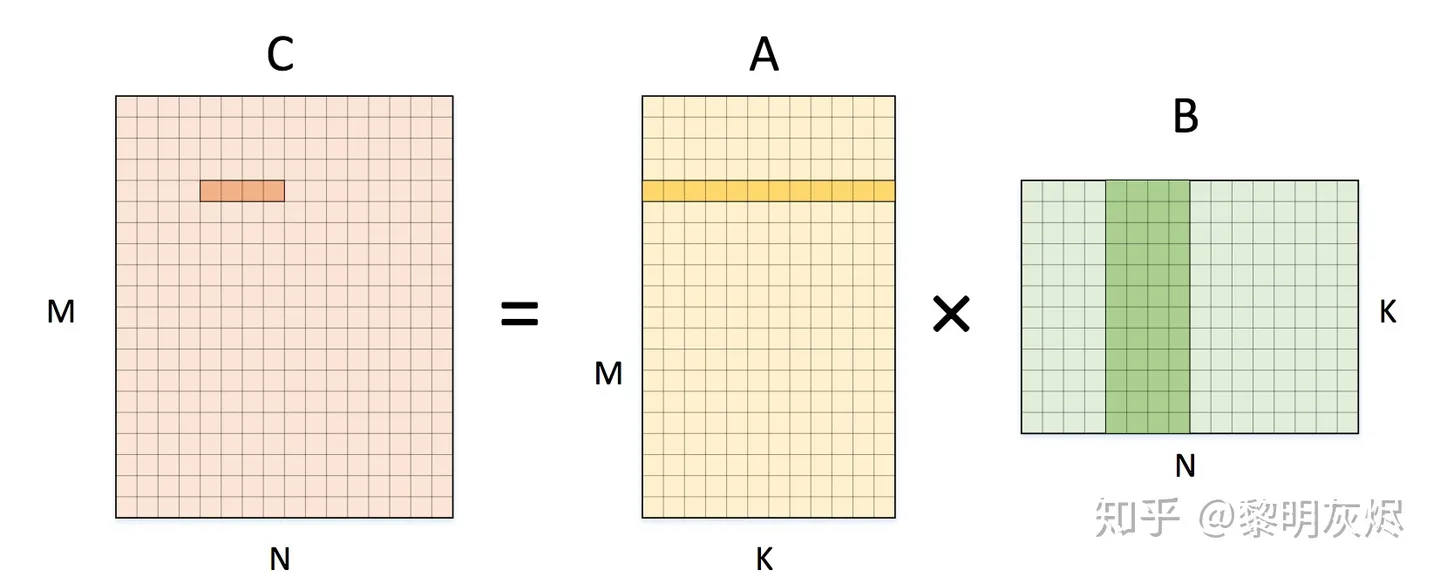
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n+=4) {
C[m][n+0] = 0;
C[m][n+1] = 0;
C[m][n+2] = 0;
C[m][n+3] = 0;
for (int k = 0; k < K; k++) {
C[m][n+0] += A[m][k] * B[k][n+0]
C[m][n+1] += A[m][k] * B[k][n+1]
C[m][n+2] += A[m][k] * B[k][n+2]
C[m][n+3] += A[m][k] * B[k][n+3]
}
}
}
计算操作数没有变化:
内存访问数也没有变化:
但是内层循环中对 A[m][k] 有四次重复访问,可以先将他读到寄存器中,达到复用的目的。
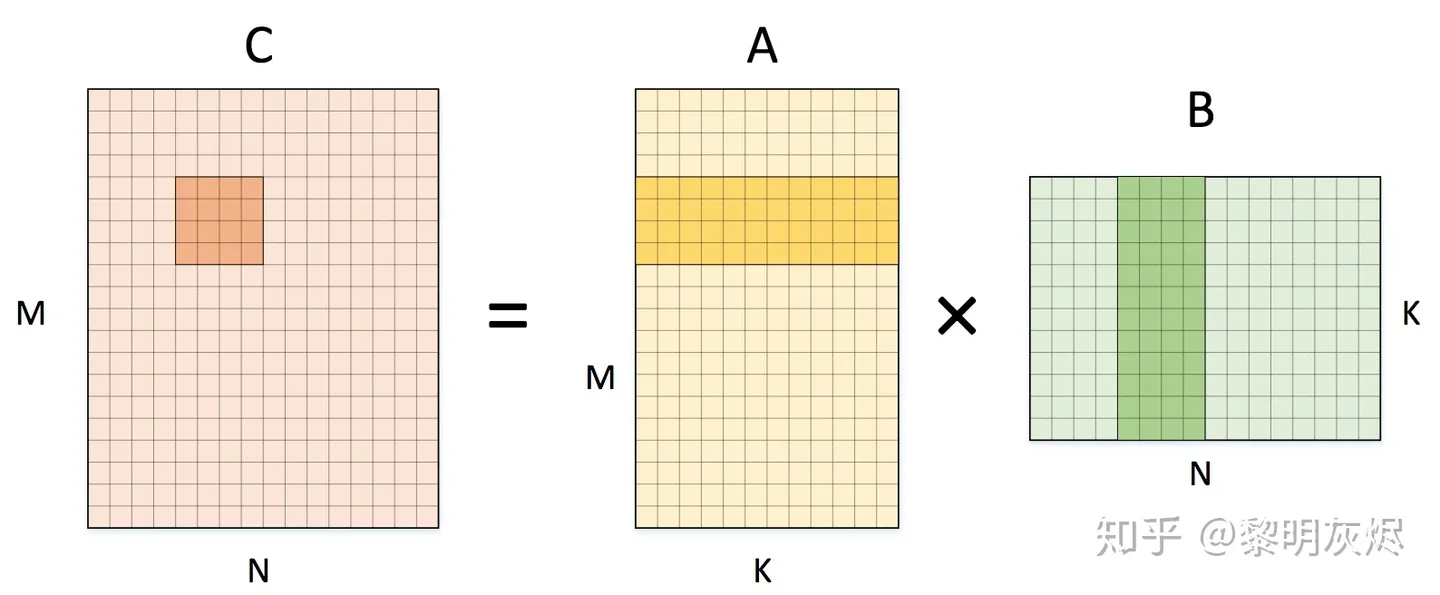
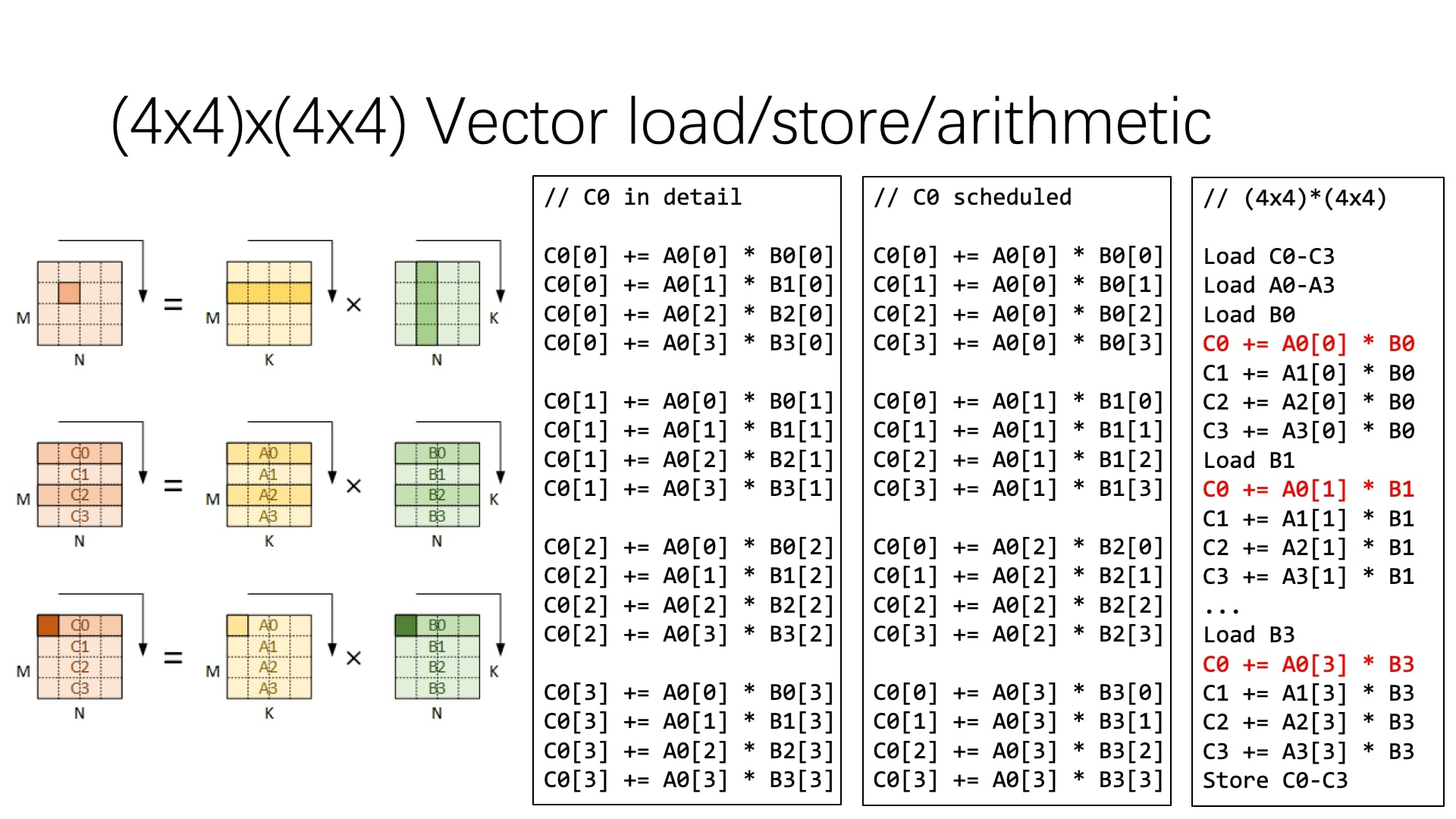
拆分为 4✖️4的小块:
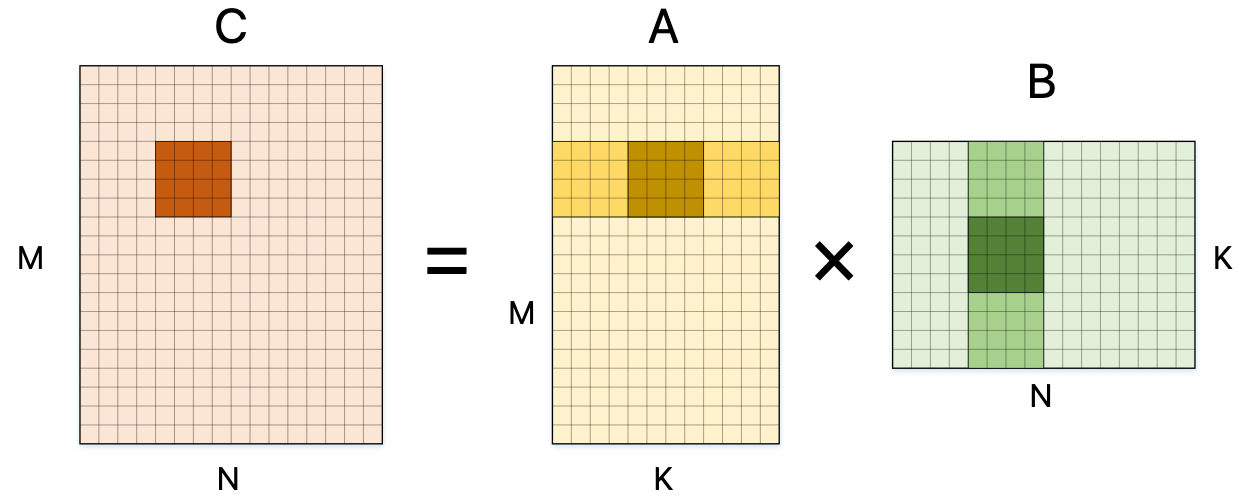
以上为针对 M, N 维度的展开,我们还可以对 K 维度进行展开:
向量化
现代处理器有 SIMD 的能力。
内存布局的优化
主要目的是保证缓存的命中率。 现代计算机的 cache line 一般为 64 Byte。